
StreamingT2V: Autoregressive Long Video Generation with Smooth Transitions from Text

Table Of Content
- What is StreamingT2V?
- StreamingT2V: Long Video Generation with Smooth Transitions from Text
- StreamingT2V Text to Video Overview
- Key Components of StreamingT2V
- Method Overview
- Detailed Method Pipeline
- StreamingSVD: An Enhanced Autoregressive Method
- Key Features of StreamingSVD
- News and Updates
- Requirements
- Setup Instructions
- Inference
- Image-to-Video
- Adjusting Hyperparameters
- Future Plans
- StreamingModelscope
- Acknowledgments
What is StreamingT2V?
Text-to-video diffusion models have made it possible to generate high-quality videos that align with text instructions, enabling the creation of diverse and personalized content. However, most existing methods focus on generating short videos, typically 16 or 24 frames, which results in abrupt cuts when extended to longer video synthesis.
StreamingT2V: Long Video Generation with Smooth Transitions from Text
To address these limitations, I introduce StreamingT2V, an autoregressive approach designed for generating long videos of 80, 240, 600, 1200, or even more frames with smooth transitions. This method ensures consistency, dynamic motion, and extendability, making it a robust solution for long video generation.
StreamingT2V Text to Video Overview
| Detail | Description |
|---|---|
| Name | StreamingT2V Text to Video |
| Purpose | Text to Video, AI Video Generator |
| GitHub Page | StreamingT2V GitHub Pages |
| Official Paper | StreamingT2V Paper on arXiv |
| Official HuggingFace | StreamingT2V HuggingFace |
| StreamingT2V Github Code | Github Code |
Key Components of StreamingT2V
StreamingT2V incorporates three main components to achieve its goals:
-
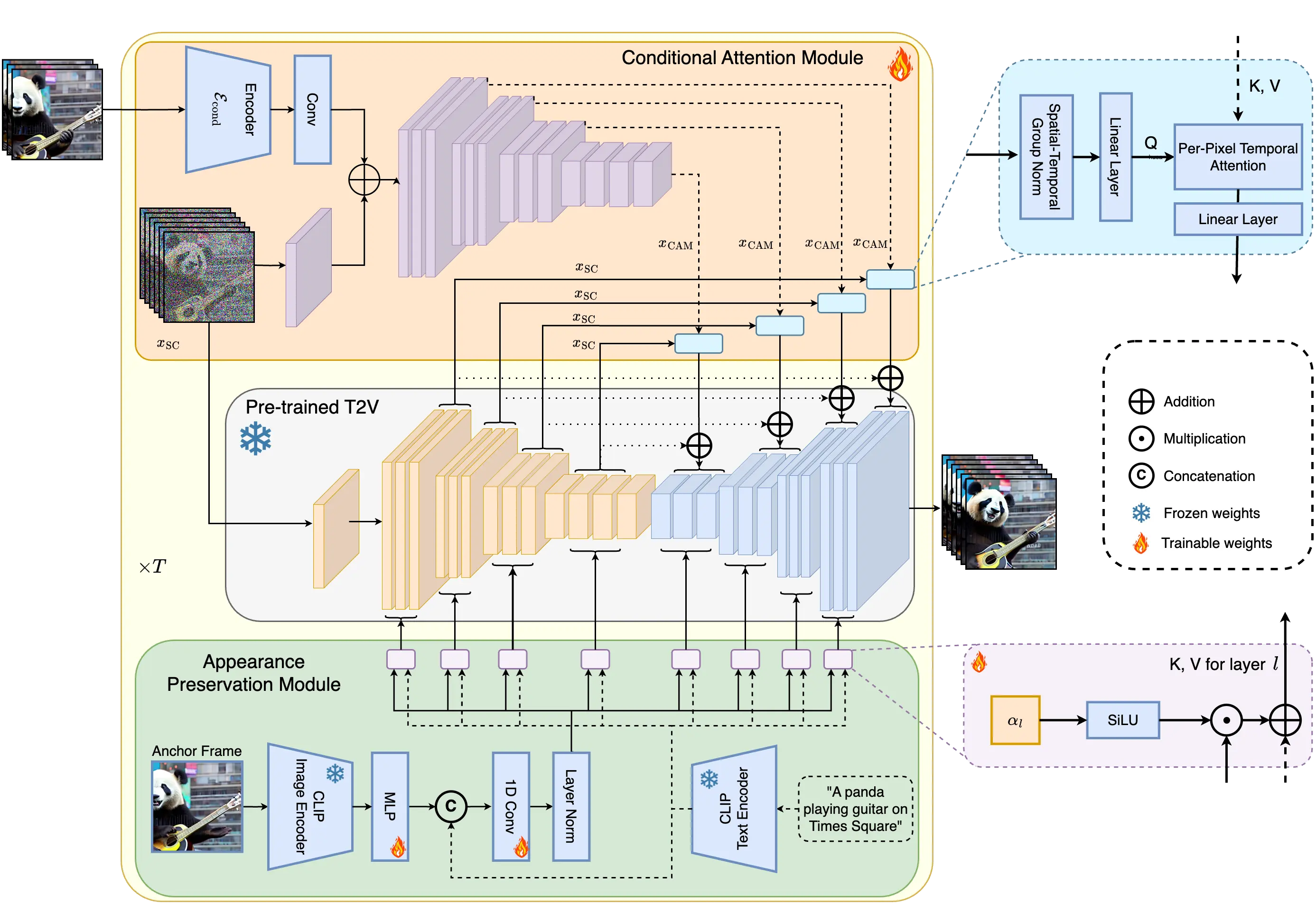
Conditional Attention Module (CAM): This short-term memory block conditions the current video generation on features extracted from the previous chunk using an attentional mechanism. This ensures smooth transitions between chunks and maintains high motion quality throughout the video.
-
Appearance Preservation Module (APM): As a long-term memory block, APM extracts high-level scene and object features from the first video chunk. It injects these features into the text cross-attentions of the video diffusion model (VDM), preventing the model from forgetting the initial scene and preserving object/scene consistency across the video.
-
Randomized Blending Approach: This technique allows the application of a video enhancer autoregressively for infinitely long videos without introducing inconsistencies between chunks. It ensures that the video remains visually coherent even as it extends in length.
Experiments demonstrate that StreamingT2V generates videos with a high degree of motion, outperforming competing image-to-video methods that often result in stagnation when applied autoregressively.
StreamingT2V stands out as a high-quality, seamless text-to-long video generator.
Method Overview
The StreamingT2V pipeline consists of three stages:
- Initialization Stage: The first 16-frame chunk is synthesized using a text-to-video model.
- Streaming T2V Stage: New content for additional frames is generated autoregressively.
- Streaming Refinement Stage: The generated long video (600, 1200 frames, or more) is enhanced autoregressively using a high-resolution text-to-short-video model, combined with the randomized blending approach.
Detailed Method Pipeline
StreamingT2V extends a video diffusion model (VDM) by integrating the Conditional Attention Module (CAM) and the Appearance Preservation Module (APM):
- CAM: Conditions the VDM on the previous chunk using a frame encoder. Its attentional mechanism ensures smooth transitions between chunks and maintains high motion quality.
- APM: Extracts high-level image features from an anchor frame and injects them into the text cross-attentions of the VDM. This preserves object and scene features throughout the autoregressive video generation process.
StreamingSVD: An Enhanced Autoregressive Method
StreamingSVD is an advanced autoregressive technique for text-to-video and image-to-video generation. It transforms SVD into a long video generator capable of producing high-quality videos with rich motion dynamics. StreamingSVD ensures temporal consistency, aligns closely with the input text or image, and maintains high frame-level image quality.
Key Features of StreamingSVD
- Temporal Consistency: Ensures smooth transitions and coherence throughout the video.
- High Motion Dynamics: Generates videos with rich motion, avoiding stagnation.
- Extendability: Successfully demonstrated with videos up to 200 frames (8 seconds), with potential for even longer durations.
StreamingSVD is part of the StreamingT2V family. Another notable implementation is StreamingModelscope, which turns Modelscope into a long-video generator capable of producing videos up to 2 minutes in length with high motion quality and no stagnation.
News and Updates
- [11/28/2024]: Memory-optimized version released!
- [08/30/2024]: Code and model released! The model weights are available on HuggingFace.
For detailed results, visit the Project Page.
Requirements
To run StreamingT2V, the following requirements must be met:
- VRAM: The default configuration requires 60 GB of VRAM for generating 200 frames. The memory-optimized version reduces this to 24 GB but operates approximately 50% slower.
- System: Tested on Linux using Python 3.9 and CUDA >= 11.8.
- FFMPEG: Ensure FFMPEG is installed.
Setup Instructions
To set up StreamingT2V, follow these steps:
-
Clone the repository:
git clone https://github.com/Picsart-AI-Research/StreamingT2V.git cd StreamingT2V/ -
Create a virtual environment and install dependencies:
virtualenv -p python3.9 venv source venv/bin/activate pip install --upgrade pip pip install -r requirements.txt -
Ensure FFMPEG is installed on your system.
Inference
Image-to-Video
To run the entire pipeline for image-to-video generation, including video enhancement and frame interpolation, execute the following commands from the StreamingT2V folder:
cd code
python inference_i2v.py --input $INPUT --output $OUTPUT- $INPUT: Path to an image file or folder containing images. Each image should have a 16:9 aspect ratio.
- $OUTPUT: Path to the folder where results will be stored.
Adjusting Hyperparameters
- Number of Frames: Add
--num_frames $FRAMESto define the number of frames to generate. Default:$FRAMES=200. - Randomized Blending: Add
--use_randomized_blending $RBto enable randomized blending. Default:$RB=False. Recommended values forchunk_sizeandoverlap_sizeare--chunk_size 38and--overlap_size 12, respectively. Note that randomized blending slows down the generation process. - Output FPS: Add
--out_fps $FPSto define the FPS of the output video. Default:$FPS=24. - Memory Optimization: Use
--use_memoptto enable memory optimizations for hardware with 24 GB VRAM. If using a previously cloned repository, update the environment and delete thecode/checkpoint/i2v_enhancefolder to ensure the correct version is used.

Future Plans
- Release a technical report describing StreamingSVD.
- Launch StreamingSVD for text-to-video generation.
- Reduce VRAM memory requirements further.
- Introduce Motion Aware Warp Error (MAWE): A proposed metric for evaluating motion quality in generated videos.
StreamingModelscope
The code for the StreamingT2V model based on Modelscope is now available. For more details, refer to the paper.
Acknowledgments
- SVD: An image-to-video method.
- Align Your Steps: A method for optimizing sampling schedules.
- I2VGen-XL: An image-to-video method.
- EMA-VFI: A state-of-the-art video-frame interpolation method.
- Diffusers: A framework for diffusion models.
Related Posts

3DTrajMaster: A Step-by-Step Guide to Video Motion Control
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.

Caracal AI: Free Tool for Handwritten Text Recognition, Extract text from Images
Caracal is a text recognition project that has been widely cloned and fine-tuned by users for specific purposes. The project leverages advanced technology for text recognition tasks, as highlighted in the provided transcript snippet.

Browser-Use Free AI Agent: Now AI Can control your Web Browser
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.