
Pyramidal Flow Matching AI: Text to video, Image to Video, Video Generator

Table Of Content
- What is Pyramid Flow?
- Pyramid Flow Overview
- Pyramidal Flow Video Generator Overview
- Key Features:
- Recent Updates:
- Table of Contents
- Installation
- Create environment using conda
- Inference
- 1. Quick Start with Gradio
- Quick Start on Google Colab
- Setup
- Download miniFLUX
- Start
- 2. Inference Code
- used for 768p model variant
- used for 768p model variant
- 3. Multi-GPU Inference
- 4. Usage Tips
- Training
- 1. Training VAE
- 2. Finetuning DiT
What is Pyramid Flow?
Video generation is a complex task that involves modeling a vast spatiotemporal space, which typically demands significant computational resources and data usage.
To address this, many existing approaches use a cascaded architecture to avoid direct training with full resolution. While this reduces computational demands, it often leads to separate optimization of each sub-stage, which can hinder knowledge sharing and limit flexibility.
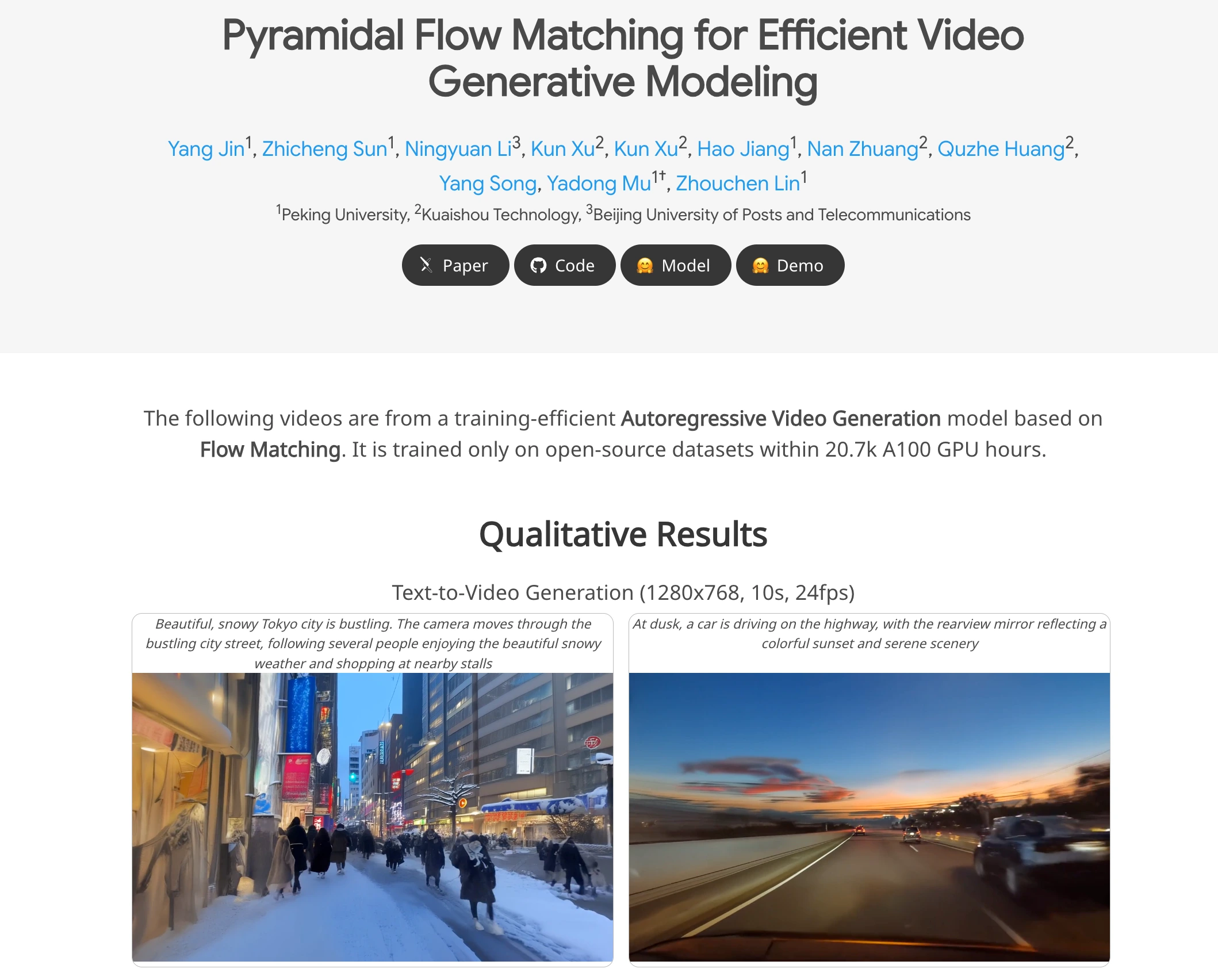
In this work, I introduce a unified pyramidal flow matching algorithm. This approach reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at full resolution.
This design enables more efficient video generative modeling. By interlinking the flows of different pyramid stages, we maintain continuity throughout the process.
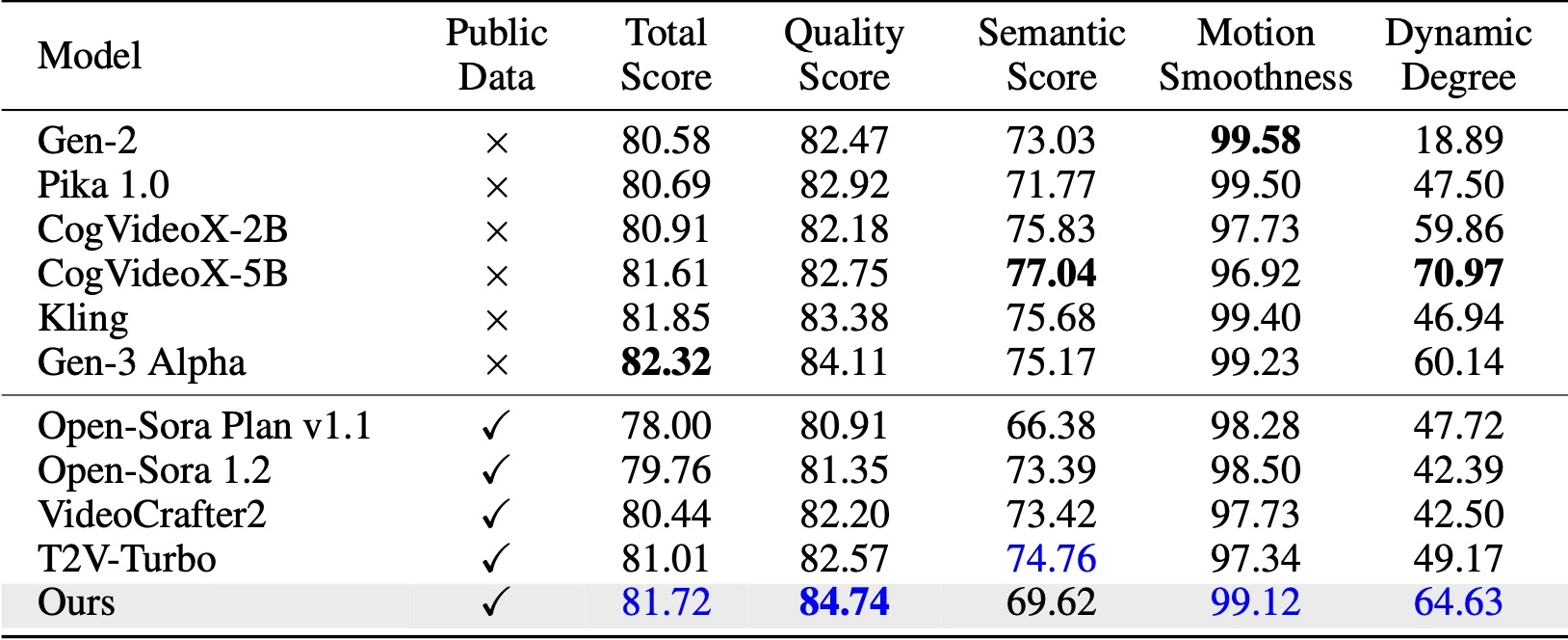
Additionally, we incorporate autoregressive video generation with a temporal pyramid to compress the full-resolution history. The entire framework is optimized in an end-to-end manner using a single unified Diffusion Transformer (DiT). Extensive experiments demonstrate that our method can generate high-quality 5-second (and up to 10-second) videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours.
Pyramid Flow Overview
This is the official repository for Pyramid Flow: https://github.com/jy0205/Pyramid-Flow, a training-efficient autoregressive video generation method based on Flow Matching. By training only on open-source datasets, it can generate high-quality 10-second videos at 768p resolution and 24 FPS. The method also naturally supports image-to-video generation.
Pyramidal Flow Video Generator Overview
| Detail | Description |
|---|---|
| Name | Pyramidal Flow Matching for Efficient Video Generative Modeling |
| Purpose | Text to Video, AI Video Generator |
| GitHub Page | Pyramidal Flow GitHub |
| Official Paper | Pyramidal Flow Paper on arXiv |
| Official HuggingFace | pyramid-flow-sd3 |
Key Features:
- 10s, 768p, 24fps: High-quality video generation.
- 5s, 768p, 24fps: Shorter video generation with the same quality.
- Image-to-video: Seamless transition from images to videos.
Recent Updates:
- 2024.11.13: Release of the 768p miniFLUX checkpoint (up to 10s).
- 2024.10.29: Release of training code for VAE, finetuning code for DiT, and new model checkpoints with FLUX structure.
- 2024.10.13: Support for multi-GPU inference and CPU offloading.
- 2024.10.11: Hugging Face demo available.
- 2024.10.10: Release of the technical report, project page, and model checkpoint.
Table of Contents
- Introduction
- Installation
- Inference
- Quick Start with Gradio
- Inference Code
- Multi-GPU Inference
- Usage Tips
- Training
- Training VAE
- Finetuning DiT
Installation
To set up the environment, I recommend using conda. The codebase currently uses Python 3.8.10 and PyTorch 2.1.2. We are actively working to support a wider range of versions.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# Create environment using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtNext, download the model from Huggingface. There are two variants: miniFLUX and SD3. The miniFLUX models support 1024p image, 384p, and 768p video generation, while the SD3-based models support 768p and 384p video generation. The 384p checkpoint generates 5-second video at 24FPS, and the 768p checkpoint generates up to 10-second video at 24FPS.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')Inference
1. Quick Start with Gradio
To get started, first install Gradio, set your model path at #L36, and then run the following command on your local machine:
python app.pyThe Gradio demo will open in your browser. Alternatively, you can try it out on Hugging Face Space, which is limited to generating 25 frames due to GPU constraints.
Quick Start on Google Colab
To quickly try out Pyramid Flow on Google Colab, run the following code:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# Download miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py2. Inference Code
To use the model, follow the inference code in video_generation_demo.ipynb. I recommend using the latest published pyramid-miniflux model, which shows significant improvements in human structure and motion stability. Here’s a simplified two-step procedure:
- Load the downloaded model:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import load_image, export_to_video
torch.cuda.set_device(0)
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration(
'PATH', # The downloaded checkpoint dir
model_name="pyramid_flux",
model_dtype=model_dtype,
model_variant='diffusion_transformer_768p',
)
model.vae.enable_tiling()
model.enable_sequential_cpu_offload()- Text-to-video generation:
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 768p model variant
width = 1280
height = 768
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
frames = model.generate(
prompt=prompt,
num_inference_steps=[20, 20, 20],
video_num_inference_steps=[10, 10, 10],
height=height,
width=width,
temp=16, # temp=16: 5s, temp=31: 10s
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale=5.0, # The guidance for the other video latent
output_type="pil",
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)- Image-to-video generation:
# used for 768p model variant
width = 1280
height = 768
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((width, height))
prompt = "FPV flying over the Great Wall"
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
frames = model.generate_i2v(
prompt=prompt,
input_image=image,
num_inference_steps=[10, 10, 10],
temp=16,
video_guidance_scale=4.0,
output_type="pil",
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)3. Multi-GPU Inference
For users with multiple GPUs, we provide an inference script that uses sequence parallelism to save memory on each GPU. This also brings a significant speedup. For example, generating a 5s, 768p, 24fps video takes only 2.5 minutes on 4 A100 GPUs, compared to 5.5 minutes on a single A100 GPU. Run the following command to use 2 GPUs:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh4. Usage Tips
- Guidance Scale: Controls visual quality. Use a value within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
- Video Guidance Scale: Controls motion. A larger value increases dynamics, while a smaller value stabilizes the video.
- 10-second Video Generation: Use a guidance scale of 7 and a video guidance scale of 5.
Training
1. Training VAE
Training VAE requires at least 8 A100 GPUs. The VAE is a MAGVIT-v2 like continuous 3D VAE, which is flexible and can be used to build your own video generative model.
2. Finetuning DiT
Finetuning DiT also requires at least 8 A100 GPUs. We provide instructions for both autoregressive and non-autoregressive versions of Pyramid Flow. The autoregressive version is more research-oriented, while the non-autoregressive version is more stable but less efficient without the temporal pyramid.
Related Posts

3DTrajMaster: A Step-by-Step Guide to Video Motion Control
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.

Caracal AI: Free Tool for Handwritten Text Recognition, Extract text from Images
Caracal is a text recognition project that has been widely cloned and fine-tuned by users for specific purposes. The project leverages advanced technology for text recognition tasks, as highlighted in the provided transcript snippet.

Browser-Use Free AI Agent: Now AI Can control your Web Browser
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.