
MinT: Temporally-Controlled Multi-Event Video Generation with Time-Based Positional Encoding

Table Of Content
- What is MinT (Mind the Time: Temporally-Controlled Multi-Event Video Generation)?
- MinT Overview
- How MinT Works?
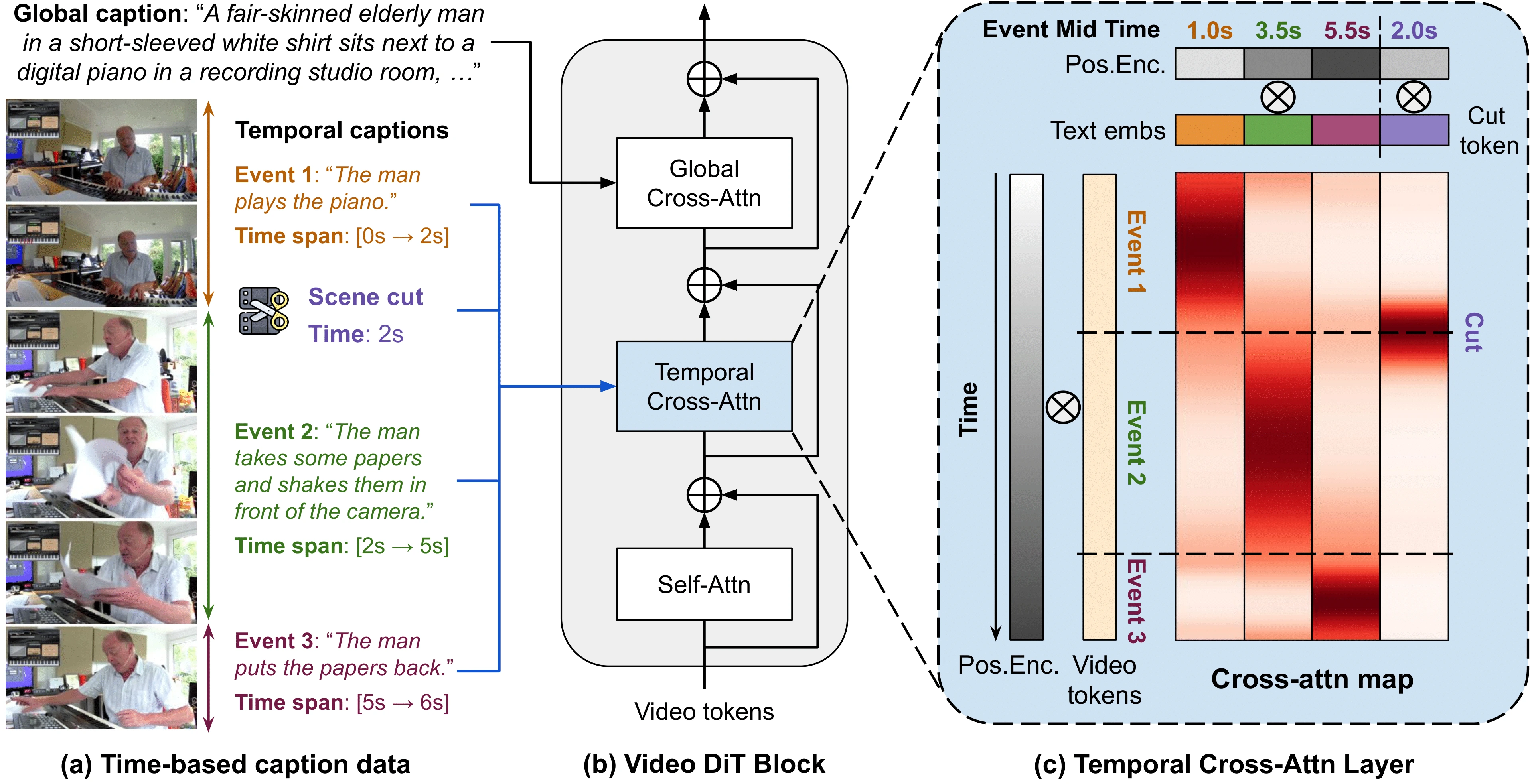
- Input Structure
- Temporal Cross-Attention Layer
- Rescaled Rotary Position Embedding (ReRoPE)
- Comparison with State-of-the-Art Models
- Comparison with Sora
- Example 1: Arm Movements
- Example 2: Typing and Standing
- MinT Results on Out-of-Distribution Prompts
- Prompt Enhancement on VBench
- Event Time Span Control
- Failure Case Analysis
- 1. Handling Human Hands and Complex Physics
- 2. Multi-Subject Scenes
- 3. Linking Subjects Between Global and Temporal Captions
- Conclusion
What is MinT (Mind the Time: Temporally-Controlled Multi-Event Video Generation)?
Real-world videos are composed of sequences of events. Generating such sequences with precise temporal control has been a challenge for existing video generators, which typically rely on a single paragraph of text as input.
When tasked with generating multiple events described in a single prompt, these methods often miss some events or fail to arrange them in the correct order. To address this limitation, I present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, allowing the model to focus on one event at a time.
To enable time-aware interactions between event captions and video tokens, we designed a time-based positional encoding method called ReRoPE. This encoding helps guide the cross-attention operation.
By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing open-source models by a significant margin.
MinT Overview
| Detail | Description |
|---|---|
| Name | MinT (Mind the Time: Temporally-Controlled Multi-Event Video Generation) |
| Purpose | Text to Video, AI Video Generator |
| GitHub Page | MinT GitHub Page |
| Official Paper | MinT Paper on arXiv |
| Twitter Thread | MinT Official |
How MinT Works?
Input Structure
Our model takes three types of inputs:
- Global Caption: A general description of the video.
- Temporal Captions: A list of captions, each describing an event and bound to a specific time span in the video.
- Scene Cut Conditioning (Optional): Information about scene transitions, if applicable.
Each temporal caption and scene cut is bound to a specific time span in the video, ensuring precise temporal control.
Temporal Cross-Attention Layer
To condition the model on time-based event captions, we introduced a new temporal cross-attention layer within the DiT (Diffusion Transformer) block. This layer allows the model to focus on the relevant event at the correct time.
Rescaled Rotary Position Embedding (ReRoPE)
We designed a novel Rescaled Rotary Position Embedding (ReRoPE) to indicate temporal correspondence between video tokens and event captions (and scene cut tokens, if used). This encoding enables MinT to control the start and end times of events, as well as the timing of shot transitions.
Comparison with State-of-the-Art Models
Comparison with Sora
Sora, a recently released model, includes a storyboard function that supports multiple text prompts and time control. We ran Sora with the same event captions and timestamps used for MinT and compared the results.
Example 1: Arm Movements
| Temporal Captions | MinT | Sora (Storyboard) |
|---|---|---|
| [0.0s → 2.3s]: A man lifts up his head and raises both arms. | Smooth and accurate execution of the event. | Missed the event or introduced undesired scene cuts. |
| [2.3s → 4.5s]: The man lowers his head and puts down both arms. | Precise timing and smooth transition. | Inaccurate timing and occasional errors in event execution. |
| [4.5s → 6.8s]: The man turns his head to the right and extends both arms to the right. | Coherent and well-timed event. | Sometimes missed the event or introduced incorrect movements. |
| [6.8s → 9.1s]: The man turns his head to the left and extends both arms to the left. | Accurate and smooth execution. | Inconsistent timing and occasional errors. |
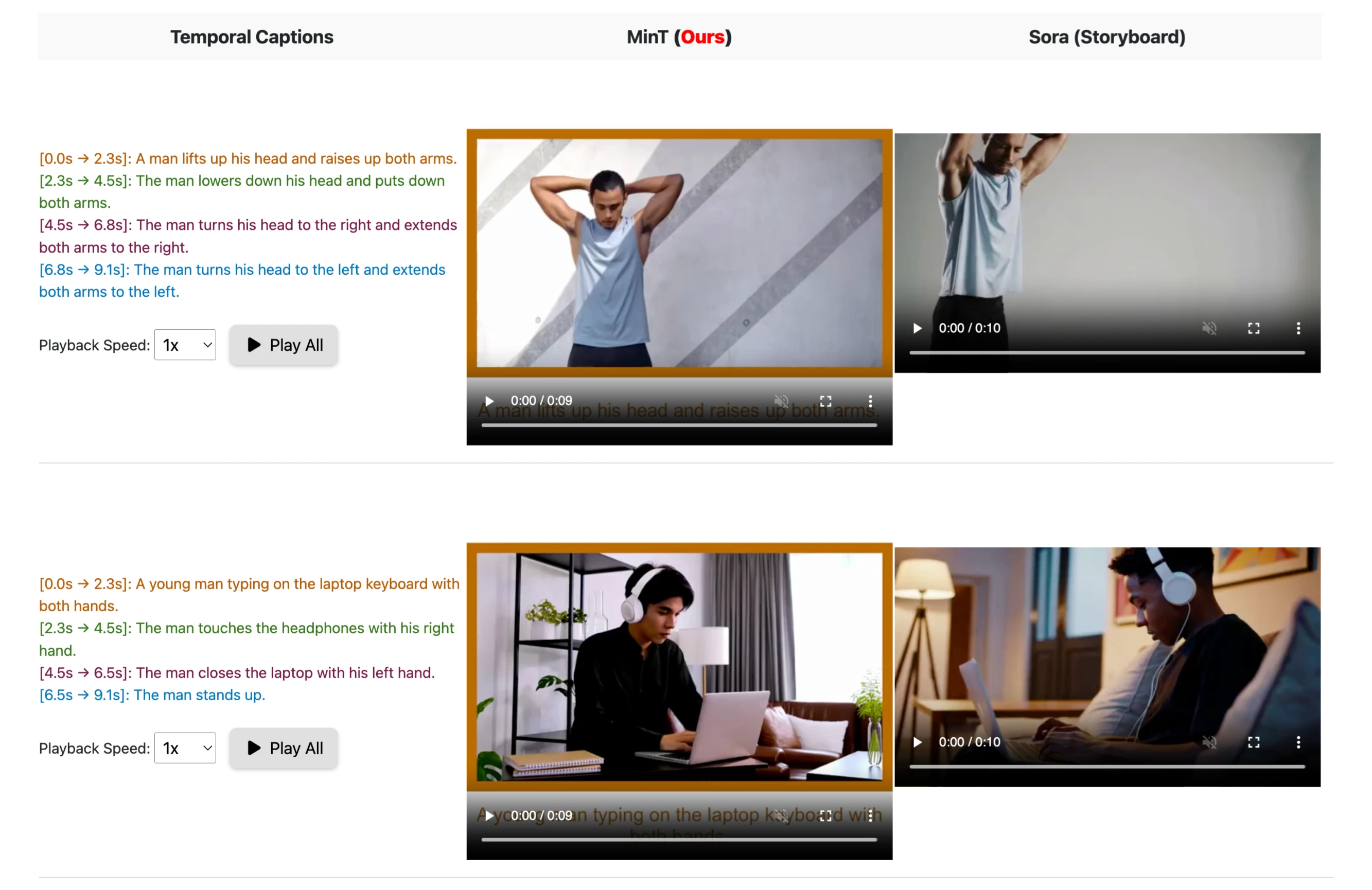
Example 2: Typing and Standing
| Temporal Captions | MinT | Sora (Storyboard) |
|---|---|---|
| [0.0s → 2.3s]: A young man typing on the laptop keyboard with both hands. | Accurate and detailed execution. | Missed some details or introduced undesired movements. |
| [2.3s → 4.5s]: The man touches the headphones with his right hand. | Precise timing and smooth transition. | Inaccurate timing and occasional errors. |
| [4.5s → 6.5s]: The man closes the laptop with his left hand. | Coherent and well-timed event. | Sometimes missed the event or introduced incorrect movements. |
| [6.5s → 9.1s]: The man stands up. | Smooth and accurate execution. | Inconsistent timing and occasional errors. |
Despite being designed for this task, Sora still sometimes misses events, introduces undesired scene cuts, and is inaccurate in event timing.
MinT Results on Out-of-Distribution Prompts
MinT is fine-tuned on temporal caption videos that mostly describe human-centric events. However, our model retains the base model's ability to generate novel concepts. Below, we showcase videos generated by MinT conditioned on out-of-distribution prompts, demonstrating its versatility.
Prompt Enhancement on VBench
To generate more interesting videos with richer motion, we used large language models (LLMs) to extend short prompts into detailed global captions and temporal captions. This allows regular users to use our model without the tedious process of specifying events and timestamps.
We compared videos generated by our base model using:
- Short Prompt: The original, brief description.
- Global Caption: The extended, detailed description.
The results show that the detailed global caption produces videos with richer motion and more engaging content. For more details, please refer to Appendix C.2 of our paper.
Event Time Span Control
MinT offers fine-grained control over event timings. In the examples below, we offset the start and end times of all events by a specific value. Each row shows a smooth progression of events, demonstrating MinT's ability to handle precise temporal adjustments. For more details, please refer to Appendix C.4 of our paper.
Failure Case Analysis
While MinT performs well in many scenarios, it is not without limitations. Below are some representative failure cases:
1. Handling Human Hands and Complex Physics
Since MinT is fine-tuned from a pre-trained video diffusion model, it inherits all its limitations. For example:
- Example 1: The model struggles to accurately depict human hands and complex physical interactions.
- Example 2: The model fails to handle multi-subject scenes, where it incorrectly binds attributes and actions to the wrong person.
2. Multi-Subject Scenes
In scenes with multiple subjects, MinT sometimes fails to bind attributes and actions to the correct person. For example:
- Example: A video with three individuals shows MinT incorrectly assigning actions to the wrong person. While our focus in this paper is on temporal binding, this issue might be addressed with spatial binding techniques, such as bounding box-controlled video generation.
3. Linking Subjects Between Global and Temporal Captions
MinT occasionally fails to link subjects between global and temporal captions. For example:
- Example: A woman described as wearing a "gray-red device on her eyes" in the global caption is prompted to "adjust the gray-red device" in the second event. However, she lifts a new device instead of adjusting the one on her eye.
We attempted simple solutions, such as running a cross-attention between text embeddings of global and temporal captions before inputting them to the DiT. However, this did not resolve the issue. We believe this "binding" problem may be solved with more training data, which we leave for future work.
Conclusion
MinT represents a significant step forward in temporally controlled multi-event video generation. By binding events to specific time spans and introducing time-based positional encoding, our model achieves precise temporal control and produces coherent, smoothly connected videos. While there are limitations, particularly in handling complex physics and multi-subject scenes, MinT outperforms existing open-source models and offers a promising foundation for future advancements in video generation.
Related Posts

3DTrajMaster: A Step-by-Step Guide to Video Motion Control
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.

Caracal AI: Free Tool for Handwritten Text Recognition, Extract text from Images
Caracal is a text recognition project that has been widely cloned and fine-tuned by users for specific purposes. The project leverages advanced technology for text recognition tasks, as highlighted in the provided transcript snippet.

Browser-Use Free AI Agent: Now AI Can control your Web Browser
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.