
Google's Imagen 3 v2: AI Image Generator

Today, I’m excited to share some idea or review of AI image generator called Imagen 3 V2. Google’s Imagen 3 v2 has emerged as the top image generator in blind tests conducted on the LM Arena (also known as Chatbot Arena). After a series of rigorous tests, Google’s latest model has taken the lead, and I’ll walk you through why this is such a big deal.
What is Imagen 3 V2?
Imagen 3 is Google DeepMind's latest text-to-image generation model, designed to produce high-quality, photorealistic images from detailed textual descriptions. It excels in accurately interpreting complex prompts, rendering fine details, and generating clear text within images. Built upon a latent diffusion model architecture, Imagen 3 efficiently handles large-scale image generation tasks.

It supports native image resolutions of 1024x1024 pixels and offers multi-stage upsampling, enabling outputs exceeding 8000x8000 pixels. This model outperforms competitors like DALL·E 3 and MidJourney v6 in prompt fidelity and image quality.
What is LM Arena?
Before diving into the results, let’s quickly recap what LM Arena is. It’s a platform where users can blind test various image generation models.
Here’s how it works:
- A user enters a prompt.
- Two image generators produce results side by side.
- The user doesn’t know which model generated which image.
- After viewing the images, the user selects the winner.
This method ensures unbiased comparisons, making it a reliable way to evaluate the performance of different AI models.
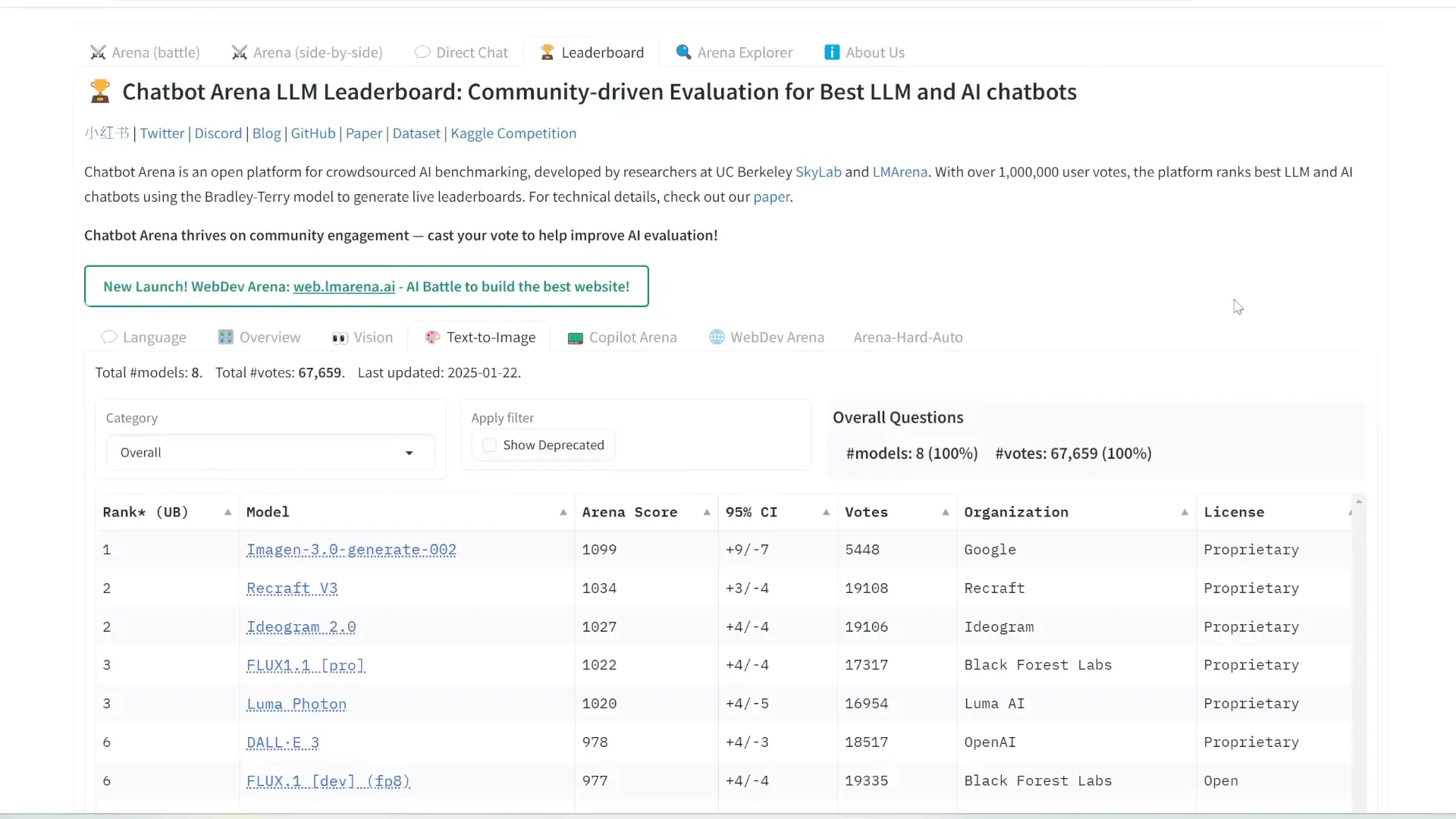
Imagen 3 v2 Takes the Lead
After countless blind tests conducted by users, Google’s Imagen 3 v2 has claimed the top spot. Here’s a breakdown of the results:
- Imagen 3 v2: Arena score of 1099
- Recraft: Second place
- Audiogram: Third place
- Flux 1.1 Pro: Fourth place
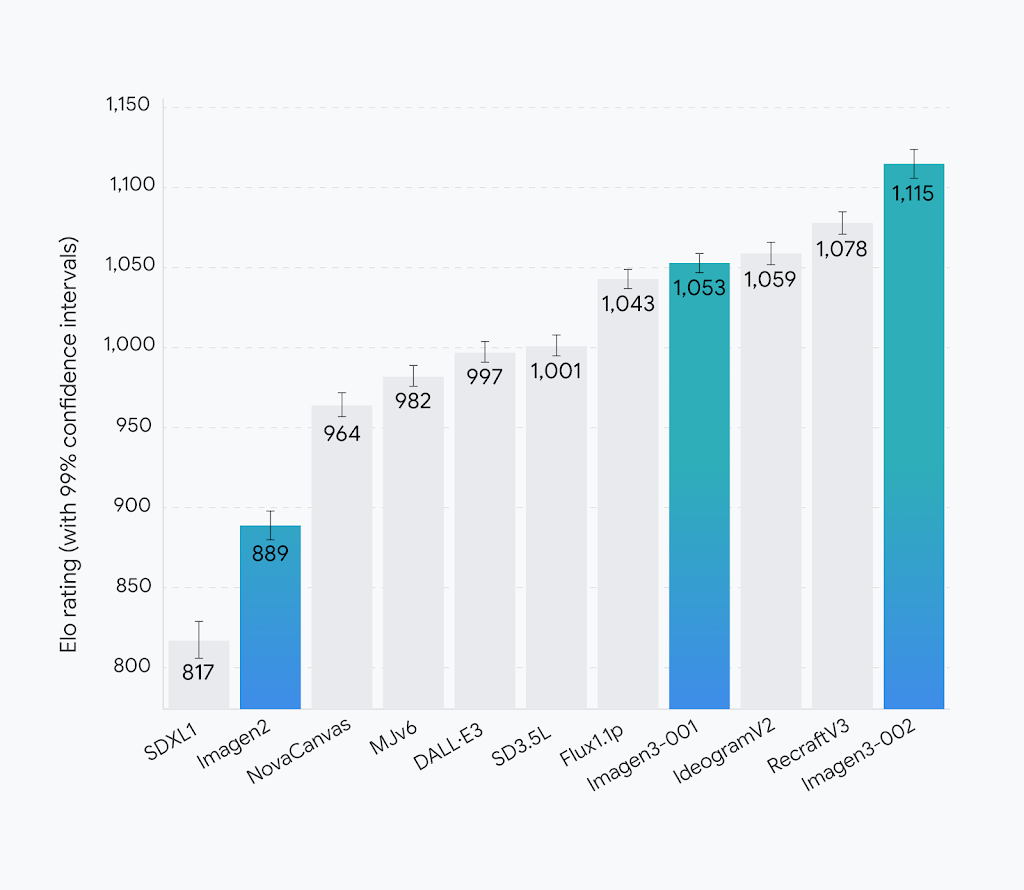
What’s fascinating is how close the scores are for the second, third, and fourth-place models—less than a 10-point difference. However, Imagen 3 v2 stands out with a score that surpasses the others by over 60 points.
This is a significant margin, showcasing its superior performance.
Trying Out Imagen 3 v2
If you’re curious to test Imagen 3 v2 yourself, you can do so on Google’s Labs platform. I’ll include a link in the description below. The platform is user-friendly and incredibly fast, making it a joy to experiment with.
To demonstrate its capabilities, I decided to put it through some challenging tests. Instead of simple prompts like portrait shots or basic scenes, I focused on more complex scenarios to truly evaluate its strengths.
Example 1: Two Hands Making a Heart Symbol
For my first test, I used the prompt: “Two hands making a heart symbol.” This is a tricky prompt because it requires the model to accurately depict human anatomy, including the positioning of fingers and hands.
Here’s what Imagen 3 v2 generated:
- Image 1: Perfectly detailed hands forming a heart.
- Image 2: Flawless execution with beautiful hand positioning.
- Image 3: Super detailed, with realistic fingers and hands.
- Image 4: All four images look flawless, with no noticeable issues.
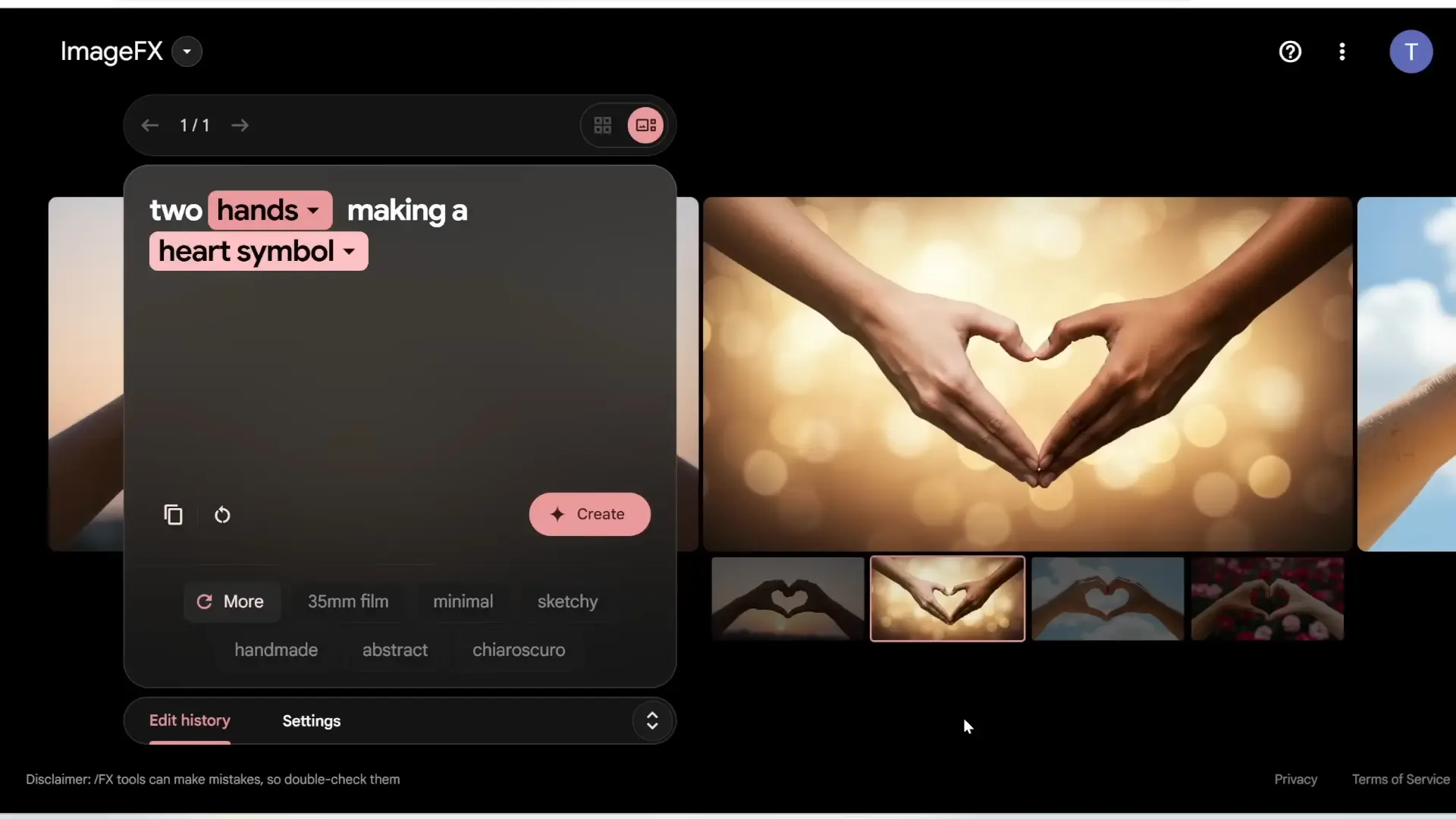
I couldn’t find any flaws in these results. The hands looked natural, and the heart symbol was clearly defined in each image.
Example 2: Testing Prompt Understanding
Next, I wanted to test the model’s ability to understand and execute a complex prompt. The prompt was:
“Photo of a red sphere on top of a blue cube. Behind them is a green triangle. On the right is a dog. On the left is a cat.”
Here’s how it performed:
- Image 1: The red sphere is on the blue cube, the green triangle is behind them, and the dog and cat are correctly positioned.
- Image 2: Nails the positioning of all objects, with realistic depictions of the dog and cat.
- Image 3: Added an extra cat, but the rest of the objects are correctly placed. The green triangle is slightly to the left rather than directly behind.
- Image 4: Perfect execution, with all elements in the correct positions.
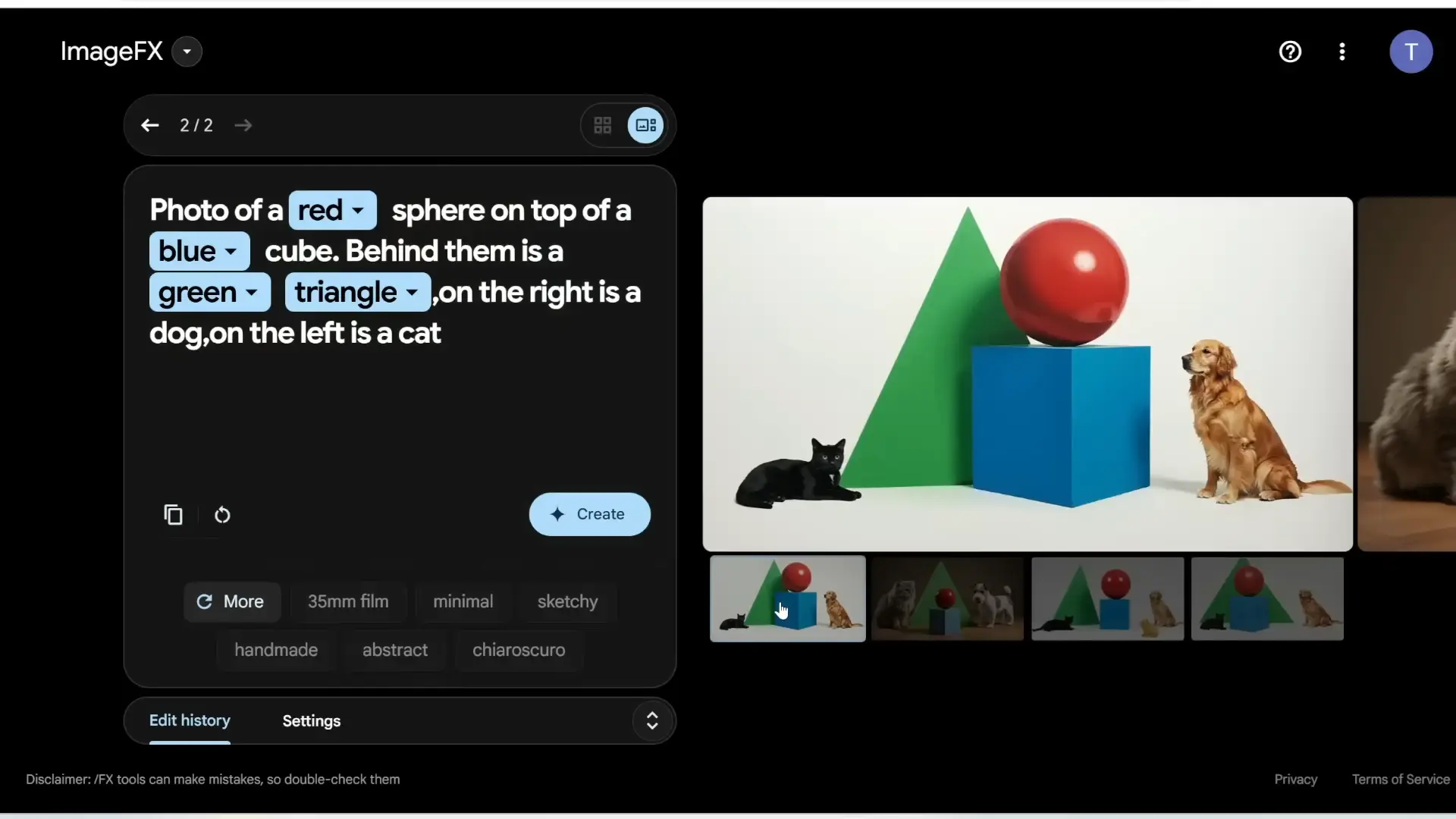
While there were minor deviations in one or two images, the overall results were impressive, especially considering the complexity of the prompt.
Example 3: Astronaut Riding a Giant Snail
For my final test, I decided to push the boundaries even further with this prompt:
“An astronaut riding a giant snail with an iridescent shell through a desert landscape. The astronaut is waving a flag that says ‘I love AI.’”
This prompt tests not only the model’s ability to handle multiple elements but also its capability to generate coherent text within the image.
Here’s what Imagen 3 v2 produced:
- Image 1: The astronaut and snail look incredibly detailed, with an iridescent shell. The flag clearly says, “I love AI.”
- Image 2: Another flawless example, with realistic textures and details.
- Image 3: The flag has an extra “A,” but the rest of the image is spot-on.
- Image 4: The shell isn’t iridescent, and the flag’s text is slightly off, but the overall composition is still impressive.
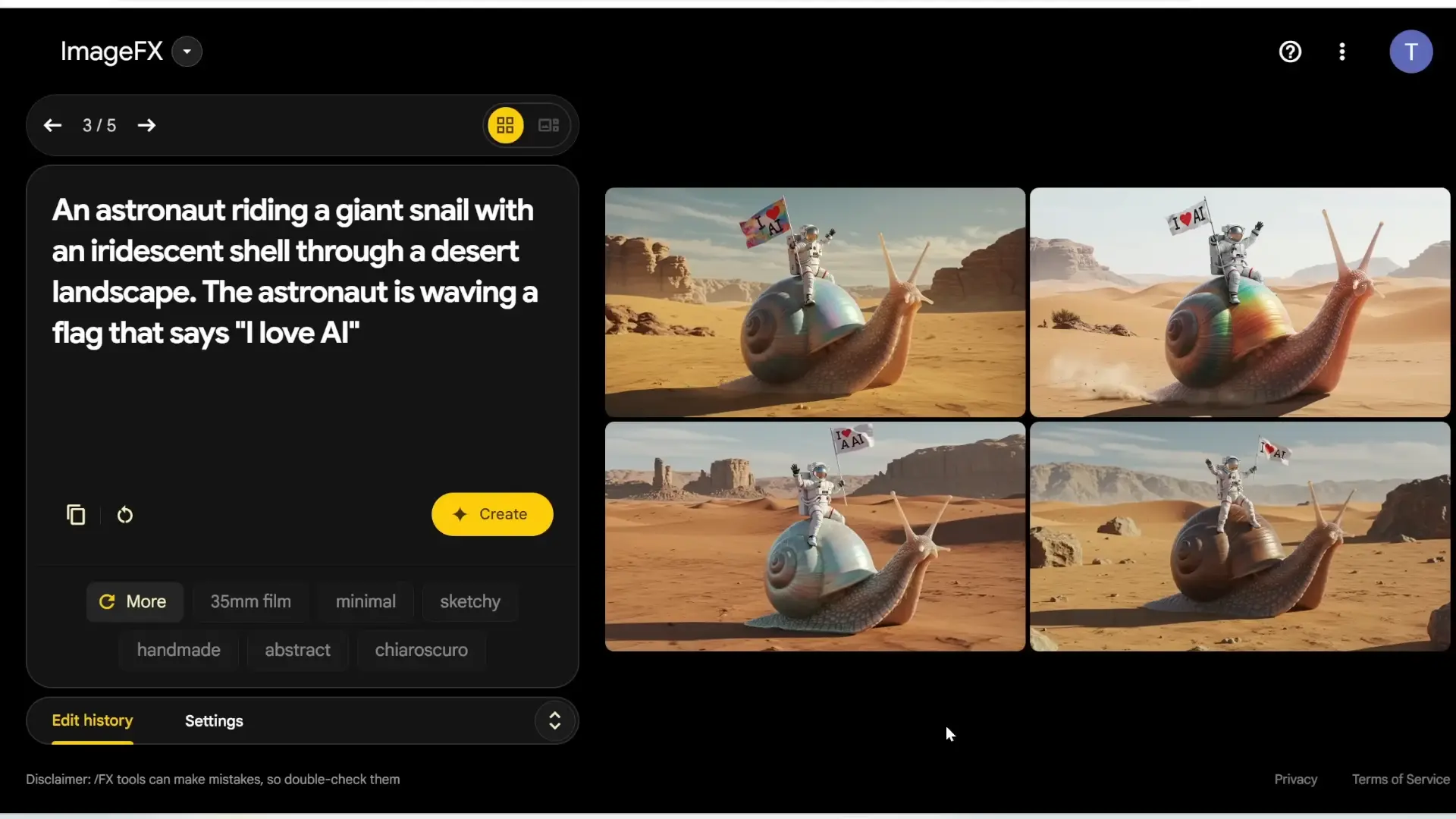
Out of the four images, two were perfect, and the other two had minor flaws. Given the complexity of the prompt, this is still an outstanding result.
Why Imagen 3 v2 Stands Out
From my preliminary tests, Imagen 3 v2 has proven to be a step above other image generation models. Here’s why:
- Detail and Realism: The images it produces are highly detailed and realistic, even in complex scenarios.
- Consistency: It consistently delivers accurate results, with fewer errors compared to other models.
- Speed: The platform is blazing fast, making it a pleasure to use.
While no model is perfect, Imagen 3 v2 comes remarkably close, especially when handling intricate prompts.
Conclusion
Google’s Imagen 3 v2 has set a new standard in AI image generation. Its ability to handle complex prompts with precision and realism is unmatched, as evidenced by its top ranking in blind tests. If you’re interested in trying it out, go to Google’s Labs platform and see for yourself.
Related Posts

3DTrajMaster: A Step-by-Step Guide to Video Motion Control
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.

Caracal AI: Free Tool for Handwritten Text Recognition, Extract text from Images
Caracal is a text recognition project that has been widely cloned and fine-tuned by users for specific purposes. The project leverages advanced technology for text recognition tasks, as highlighted in the provided transcript snippet.

Browser-Use Free AI Agent: Now AI Can control your Web Browser
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.