
DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models

In this article, I will explore a research paper titled DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for High Fidelity and Temporal Consistency.
This paper introduces a novel diffusion-based framework called DiffVSR, designed to address the challenges of real-world video super-resolution.
What makes this work stand out is its ability to achieve high visual quality and maintain temporal consistency in upscaled videos, solving issues that many other methods struggle with.
What is DiffVSR?
DiffVSR is a diffusion-based framework specifically developed for real-world video super-resolution. The goal of this framework is to enhance the quality of low-resolution videos while ensuring that the upscaled results are both visually appealing and temporally consistent.

Temporal consistency refers to the smoothness and coherence of motion across video frames, which is crucial for creating realistic and high-quality video outputs.
The researchers behind DiffVSR have introduced several key innovations to achieve these results. These innovations focus on two main aspects: intra-sequence coherence and inter-sequence stability.
DiffVSR Model Overview:
| Feature | Details |
|---|---|
| Model Name | DiffVSR |
| Functionality | Real-world video super-resolution using diffusion models |
| Paper | arxiv.org/abs/2401.05335 |
| Project Page | xh9998.github.io/DiffVSR-project |
| Key Components | Multiscale Temporal Attention Module, Temporal-Enhanced VA Decoder |
| Main Features | Intra-sequence coherence, Inter-sequence stability |
| Training Strategy | Progressive learning from simple to complex degradations |
| Applications | Video upscaling, restoration, quality enhancement |
Intra-Sequence Coherence:
Intra-sequence coherence ensures that the video looks consistent within a single scene. To achieve this, the researchers developed two critical components:
- Multiscale Temporal Attention Module: This module helps capture detailed motion information across different scales, ensuring that the upscaled frames accurately represent the motion present in the original low-resolution video.
- Temporal-Enhanced VA Decoder: This decoder works alongside the attention module to maintain spatial accuracy, ensuring that the upscaled frames are not only visually sharp but also consistent with the motion dynamics of the original video.
Together, these components ensure that the upscaled video maintains a high level of detail and accuracy within each scene.
Inter-Sequence Stability:
Inter-sequence stability focuses on ensuring that the video looks stable and consistent across different scenes or shots. To address this, the team introduced two innovative techniques:
- Noise Rescheduling Mechanism: This mechanism helps create smoother transitions between frames by adjusting the noise levels during the upscaling process.
- Interweave Latent Transition Approach: This approach ensures that the transitions between different scenes are seamless and consistent, without adding unnecessary complexity to the training process.
By combining these techniques, DiffVSR achieves a high level of stability across different scenes, making the upscaled video look more natural and cohesive.
Progressive Learning Strategy:
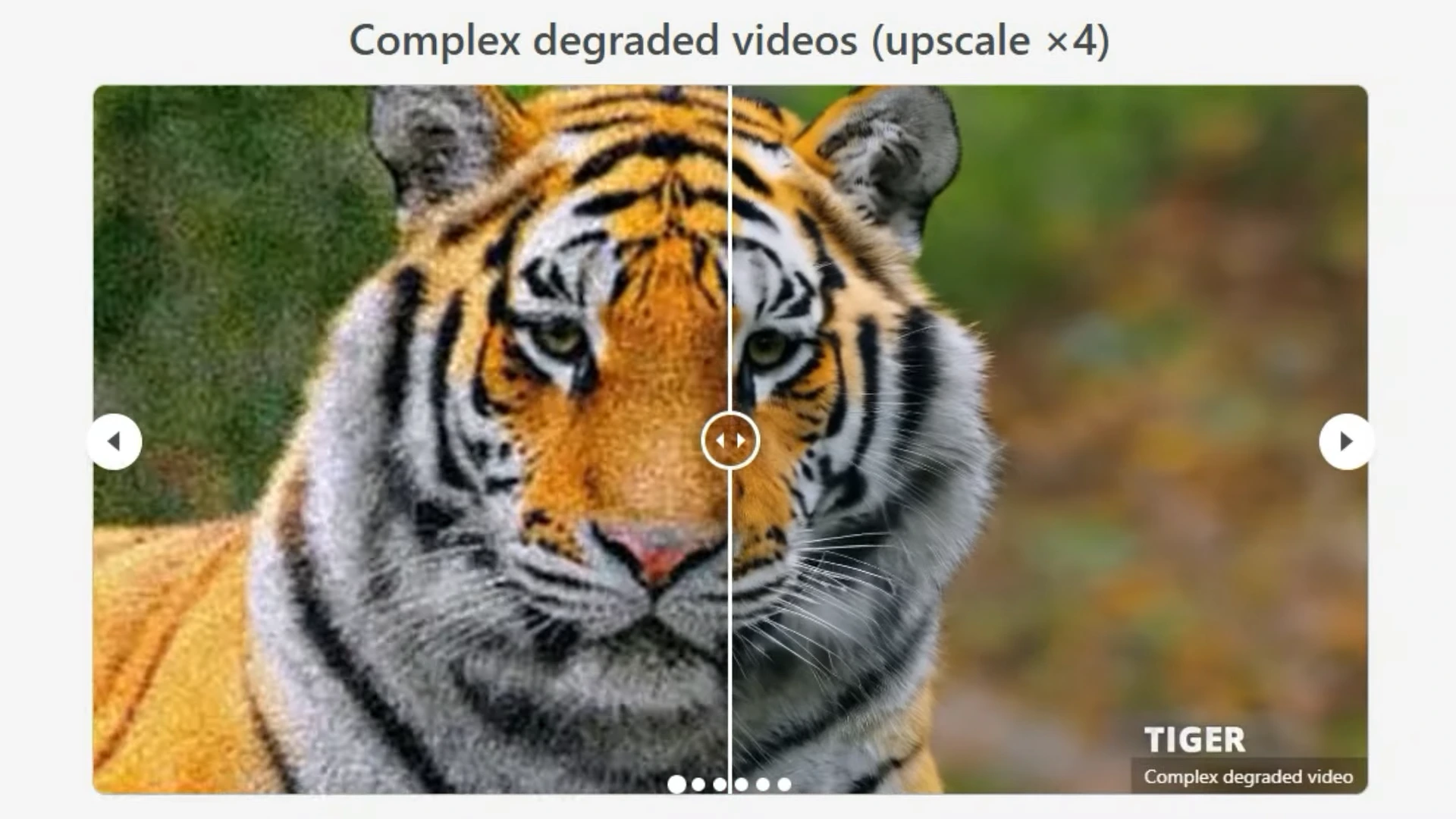
One of the challenges in real-world video super-resolution is dealing with various types of video degradation, such as noise, blur, and compression artifacts. To address this, the researchers designed a progressive learning strategy for training DiffVSR.

This strategy involves transitioning from simple to complex degradation scenarios during the training process. Here’s how it works:
- The model is first trained on videos with simple degradations, such as minor noise or blur.
- As training progresses, the model is exposed to more complex degradation scenarios, such as severe noise, compression artifacts, and other real-world distortions.
This progressive approach enables DiffVSR to handle a wide range of real-world video degradation scenarios effectively. Additionally, it makes the model robust even when high-quality video data is limited, which is often the case in real-world applications.
Performance and Results:
The paper highlights that DiffVSR outperforms existing state-of-the-art video super-resolution methods in both visual quality and temporal consistency.
- Visual Quality: DiffVSR produces upscaled videos with exceptional clarity and detail, making them visually indistinguishable from high-resolution originals.
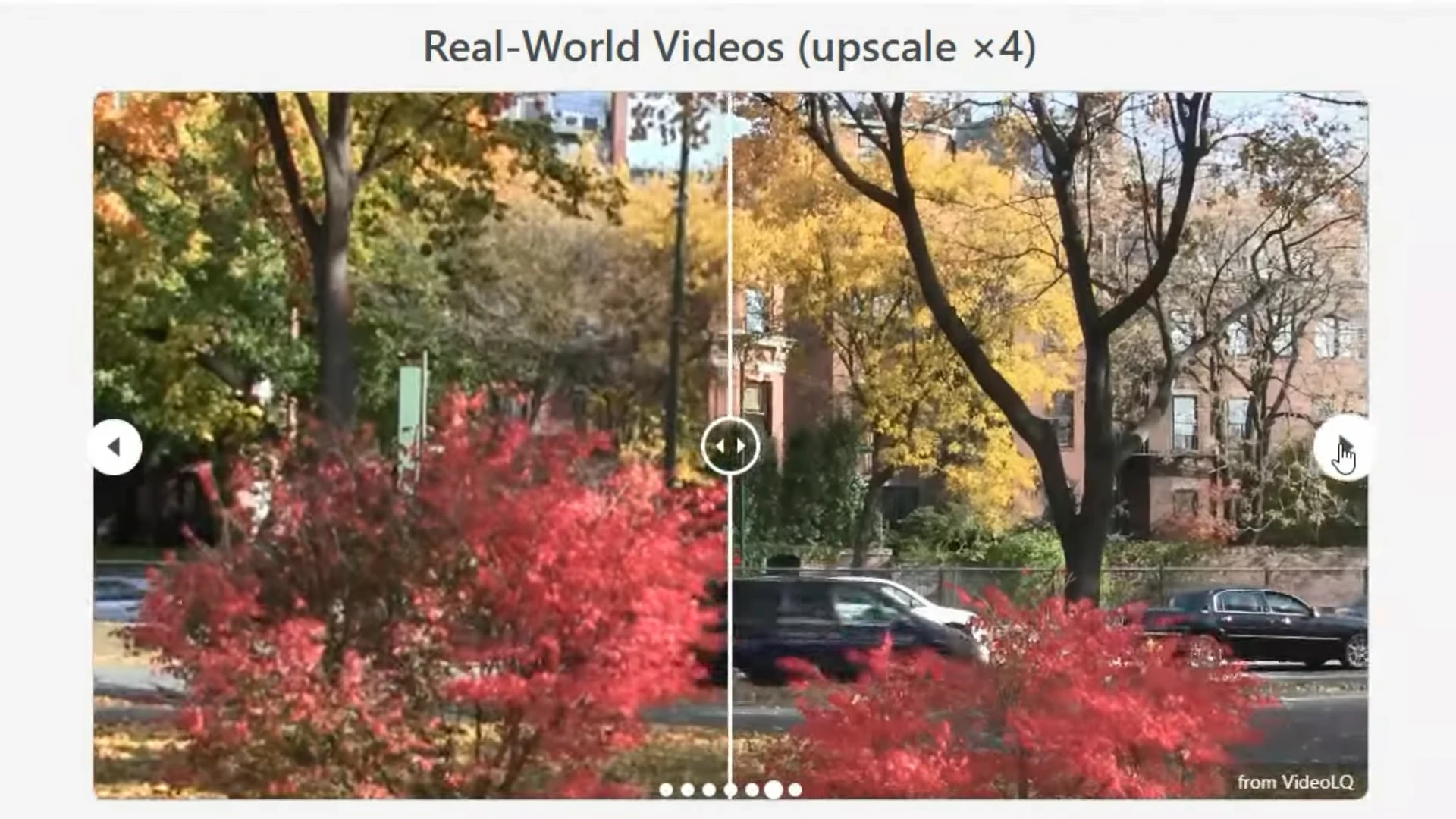
- Temporal Consistency: The upscaled videos maintain smooth and consistent motion across frames, ensuring a natural viewing experience.
These results demonstrate that DiffVSR sets a new benchmark for real-world video super-resolution, offering a significant improvement over existing methods.
Conclusion
In conclusion, DiffVSR represents a major advancement in the field of video super-resolution. By incorporating diffusion models and innovative techniques for intra-sequence coherence and inter-sequence stability, this framework achieves high fidelity and temporal consistency in upscaled videos. The progressive learning strategy further enhances its ability to handle real-world video degradation scenarios effectively.
DiffVSR not only surpasses existing methods but also opens the door for high-quality video restoration in various applications, from entertainment to surveillance and beyond. This research sets a new standard for real-world video super-resolution and paves the way for future innovations in the field.
Related Posts

3DTrajMaster: A Step-by-Step Guide to Video Motion Control
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.

Caracal AI: Free Tool for Handwritten Text Recognition, Extract text from Images
Caracal is a text recognition project that has been widely cloned and fine-tuned by users for specific purposes. The project leverages advanced technology for text recognition tasks, as highlighted in the provided transcript snippet.

Browser-Use Free AI Agent: Now AI Can control your Web Browser
Browser Use is an AI-powered browser automation framework that lets AI agents control your browser to automate web tasks like scraping, form filling, and website interactions.